谁在用Runtime Virtual Texture这个技术
· UBI在2016年公布了在Far Cry 4中使用的Adaptive Virtual Texture其中就包含Runtime virtual texture.
·UE在4.25版本发布了Runtime Virtual Texture
·鹅厂大佬公布天涯明月刀中使用了Runtime Virtual Texture,表示2层以上的混合就能表现出明显的性能优势
为什么需要Runtime Virtual Texture
- 你要做任何的大型的景观,就绕不开使用Unity Terrain/ UE4 Landscape这样的多层混合材质巨型动态Mesh。
- 从早年的world machine到现在流行的Houdini在地形制作这个部分都在疯狂地丰富一个东西—图层,8层,堪堪够用而已。
8层在十年前你可以认为是8张颜色贴图加两张控制图的混合,十张,好像是有点多,但是现在是PBR的时代,以Unity的Terrain材质为例8层意味着
(1 Albeto + 1 Normal + 1 Detail[AO R + Metal G + Roughness A])* 8 + 2 Control Map = 26次贴图采样
即每个像素,每帧都会有26次贴图采样。这就是为什么Unity官方推荐移动平台不要超过4层的原因。你以为4层就没事了吗?这个标准只能保证中端设备能跑30帧且烫不烫完全不care。
原理
Runtime Virtual Texture做的事情非常简单,把Terrain Mesh分块,把每块的26张贴图合并成2张render target,这样我们渲染的时候不管有多少图层到了渲染的时候都只有2个贴图采样,但是显存必然是有更大的开销的,空间换时间不多废话。
这里必须提出来一个问题,如果我们完全用静态资源,我们的资源到底有多大?以git工程的示例场景为例,一个传统的RPG视角,我们的LOD 0最小切割到8m * 8m,这样的一块在视角内要满足2k分辨率,需要至少1024分辨率的贴图,当然测试下来512也是可以忍的。对于一块512的Terrain,我们的贴图需求是 4096套1024贴图(albeto + normal + detail),这个资源量,再加上mipmap的开销
一、RVT核心原理
- 虚拟纹理机制
RVT通过逻辑上的无限大纹理动态加载局部所需纹理,类似内存分页管理:
- Feedback阶段:低分辨率渲染获取当前视野所需纹理的mipmap等级和位置信息(RGB存储格子坐标与mip等级)
- PageTable管理:维护动态更新的页表,记录纹理加载状态和物理存储位置(LRU算法优化Tile复用)
- TileTexture烘焙:通过MRT(多渲染目标)实时烘焙Diffuse、法线等数据到物理贴图集
- 移动端简化方案
- 四叉树动态分块:根据相机距离划分地形区块,每块分配相同尺寸贴图,用
Texture2DArray存储(索引即数组下标),避免传统RVT的复杂空间管理 - 分帧加载:限制每帧细分/合并操作次数(如每帧最大细分4次),避免卡顿
二、关键实现步骤
- 四叉树动态LOD管理
- 数据结构:节点记录坐标(x,z)、尺寸(size)、物理贴图索引(physicTexIndex)及父子节点引用。
- 合并与细分:合并:当节点远离相机时,回收子节点贴图索引,用父节点低精度贴图覆盖。细分:靠近相机时分裂为4个子节点,分配新索引加载高精度贴图。
- 帧更新优化:每帧遍历叶节点队列,按LOD变化决策合并/细分,交换双队列避免GC
- 物理贴图生成
- Blit替代相机渲染:避免传统相机渲染地形Mesh的开销,直接通过Shader一次性采样所有地表纹理(如16层)输出到
Texture2DArray - 索引贴图映射:根据地形UV生成索引贴图,存储节点起始坐标、尺寸、贴图数组索引,Shader采样时直接计算实际UV
三、移动端专项优化
1、纹理与内存管理
- AlphaMap分组:每4种纹理共用一张AlphaMap,减少贴图切换(如12种纹理需3张图)
- 异步加载:通过
AsyncGPUReadback异步回读Feedback数据,延迟一帧使用避免阻塞
2、海洋主题适配
- 岛屿独立节点:将岛屿抽象为独立四叉树节点,支持随机分布与紧密数据排列
- 棋盘格烘焙:以512×512米为单位烘焙地形数据,适配航海类大世界
四、工程实践建议
1、开发管线集成
Houdini流程:用Houdini生成地形/道路/桥梁,导出Unity后通过HLOD System预处理(减面+合批),减少70%+ DrawCall
光照方案:
- 近距离:级联阴影(CSM)
- 远距离:体素化阴影(VSM)+ LightProbe流式加载
2、调式工具
- 可视化Feedback贴图与PageTable状态,实时监控Tile加载情况
- 负反馈性能调节系统:动态限制高负载操作(如分帧细分)
其实吧RVT的核心架构一张图就能说清楚
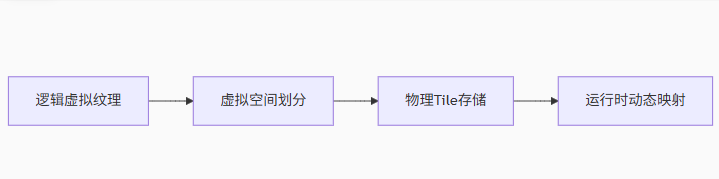
与传统的贴图方案对比优势
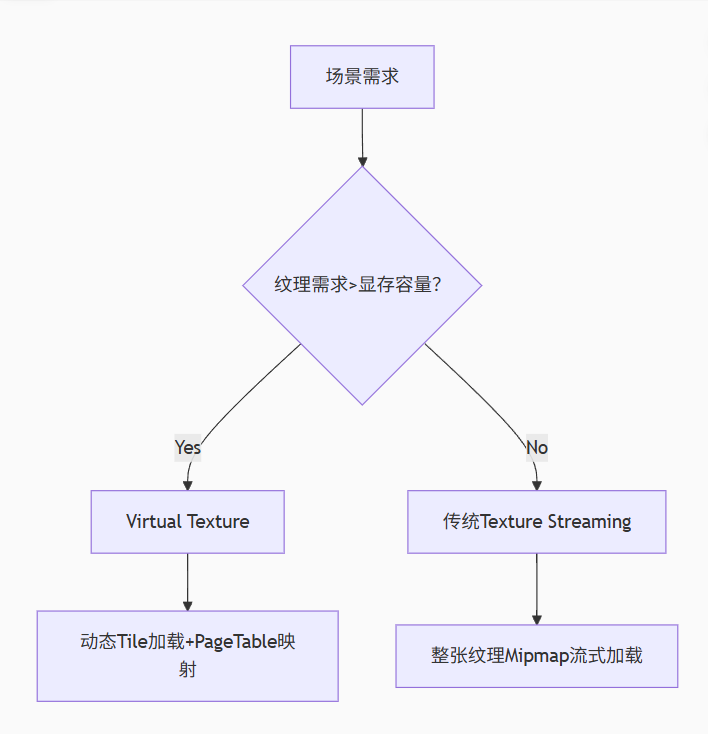
优势场景:
- 超大规模地形(如飞行模拟中的全球地表)
- 程序化生成世界(无限地形动态烘焙)
- 高清材质统一管理(避免重复资源)
下面我一步一步从前往后梳理整个过程,以及在Unity的实现技术细节。
格子
我们会根据可视范围把范围内的所有地块划分成格子,格子越小,分到固定分辨率大小的贴图清晰度就越高,当然性能也就越差。UE是固定格子,直接是以地形为单位划分的。但是对于一个超大世界来讲,这个范围是变化的,所以格子也是动态变化的。这里只交待一个概念,后面在各个部分的时候再详细讲。
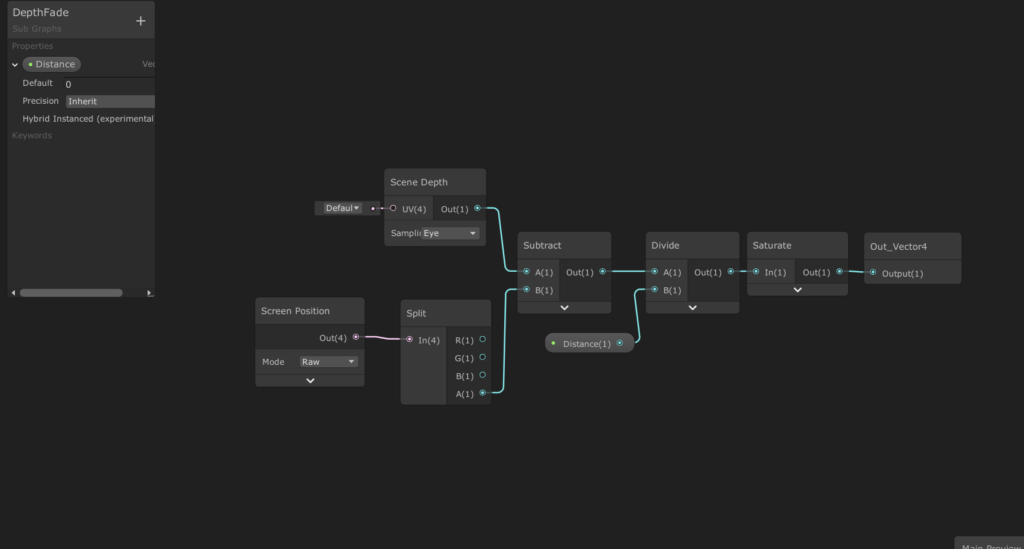
FeedBack
feedback有点类似于遮挡剔除,会预先烘一个低分辨率的贴图信息,rgb分别表示格子坐标,mipmap等级。格子坐标通过世界坐标在可视区域,以及格子的大小这些参数就能算出来。mipmap等级则是通过偏导求出来的。
feed_v2f VTVertFeedback(feed_attr v)
{
feed_v2f o;
UNITY_SETUP_INSTANCE_ID(v);
#if defined(UNITY_INSTANCING_ENABLED)
float2 patchVertex = v.vertex.xy;
float4 instanceData = UNITY_ACCESS_INSTANCED_PROP(Terrain, _TerrainPatchInstanceData);
float2 sampleCoords = (patchVertex.xy + instanceData.xy) * instanceData.z; // (xy + float2(xBase,yBase)) * skipScale
float height = UnpackHeightmap(_TerrainHeightmapTexture.Load(int3(sampleCoords, 0)));
v.vertex.xz = sampleCoords * _TerrainHeightmapScale.xz;
v.vertex.y = height * _TerrainHeightmapScale.y;
v.texcoord = sampleCoords * _TerrainHeightmapRecipSize.zw;
#endif
VertexPositionInputs Attributes = GetVertexPositionInputs(v.vertex.xyz);
o.pos = Attributes.positionCS;
float2 posWS = Attributes.positionWS.xz;
o.uv = (posWS - _VTRealRect.xy) / _VTRealRect.zw;
return o;
}
float4 VTFragFeedback(feed_v2f i) : SV_Target
{
float2 page = floor(i.uv * _VTFeedbackParam.x);
float2 uv = i.uv * _VTFeedbackParam.y;
float2 dx = ddx(uv);
float2 dy = ddy(uv);
int mip = clamp(int(0.5 * log2(max(dot(dx, dx), dot(dy, dy))) + 0.5 + _VTFeedbackParam.w), 0, _VTFeedbackParam.z);
return float4(page / 255.0, mip / 255.0, 1);
}
在unity urp配置渲染管线,只需要添加一个renderdata,配置好参数
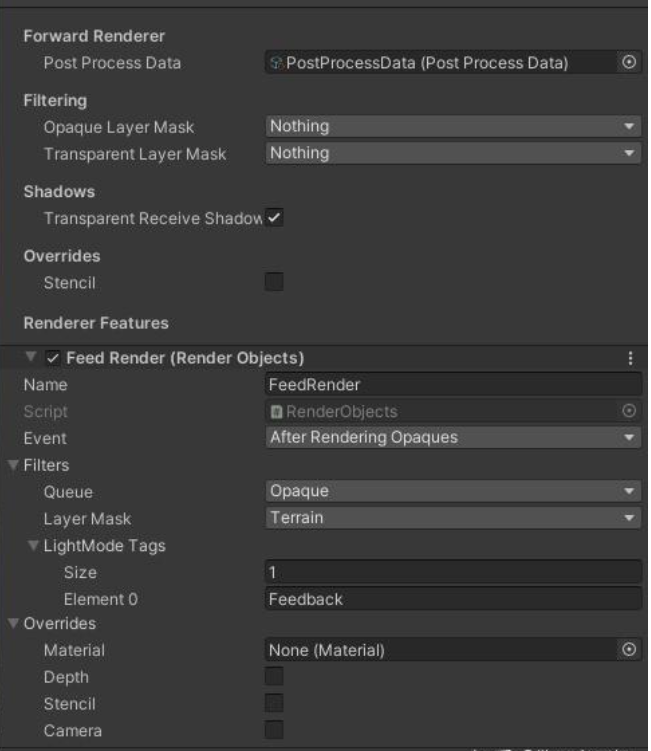
然后在地形里边添加一个feedback的pass
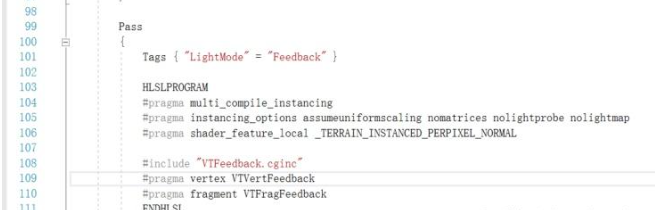
然后在feedback相机上选择这个render
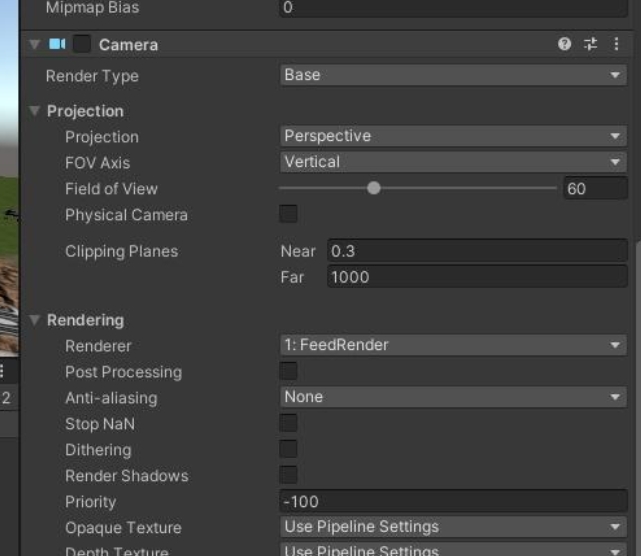
feedback的相机要保证跟场景相机参数一样,可以写个脚本复制参数,然后把这个相机挂在场景相机,transform归零就ok了。这里我把camera的enable去掉了,我自己来调用render,因为这里可以自己控制更新频率。
这里渲染的时候分辨率降低一半,如果觉得还不够可以再降一些,这里为啥不一开始就用低分辨率呢,是因为,先以一个差不多的分辨率精度比较高,再降是取最大的mipmap等级,这样会保证正确性。
float4 GetMaxFeedback(float2 uv, int count)
{
float4 col = float4(1, 1, 1, 1);
for (int y = 0; y < count; y++)
{
for (int x = 0; x < count; x++)
{
float4 col1 = tex2D(_MainTex, uv + float2(_MainTex_TexelSize.x * x, _MainTex_TexelSize.y * y));
col = lerp(col, col1, step(col1.b, col.b));
}
}
return col;
}
这里之所以对分辨率要求这么高,是因为我们需要把贴图数据从rendertarget里取出到cpu来读取数据。
// 发起异步回读请求 m_ReadbackRequest = AsyncGPUReadback.Request(texture);
这是一个异步请求,我们可能有一个延迟,也就是说一般是这一帧使用的是上一帧的feedback
PageTable
页表是一个mipmap层级结构的表,比如说我们的格子是一个256×256的矩阵,那么mipmap为0的等级就是256×256的cell,mipmap为1的就是128×128的cell,依次类推。cell的上面除了存放mipmap等级,占据的rect,还有page的加载情况。
public class TableNodeCell
{
public RectInt Rect { get; set; }
public PagePayload Payload { get; set; }
public int MipLevel { get; }
public TableNodeCell(int x, int y, int width, int height,int mip)
{
Rect = new RectInt(x, y, width, height);
MipLevel = mip;
Payload = new PagePayload();
}
}
这里要注意的是我们这的pagetable是个可变化的,针对移动是调整后面单独拎出来说。
上面feedback处理完得到一张feedback的贴图,上面各个像素表示需要显示的cell以及mipmap等级。我们可以通过这个信息,去触发加载TileTexture。
/// <summary>
/// 激活页表
/// </summary>
private TableNodeCell ActivatePage(int x, int y, int mip)
{
if (mip > MaxMipLevel || mip < 0 || x < 0 || y < 0 || x >= TableSize || y >= TableSize)
return null;
// 找到当前页表
var page = m_PageTable[mip].Get(x, y);
if(page == null)
{
return null;
}
if(!page.Payload.IsReady)
{
LoadPage(x, y, page);
//向上找到最近的父节点
while(mip < MaxMipLevel && !page.Payload.IsReady)
{
mip++;
page = m_PageTable[mip].Get(x, y);
}
}
if (page.Payload.IsReady)
{
// 激活对应的平铺贴图块
m_TileTexture.SetActive(page.Payload.TileIndex);
page.Payload.ActiveFrame = Time.frameCount;
return page;
}
return null;
}
/// <summary>
/// 加载页表
/// </summary>
private void LoadPage(int x, int y, TableNodeCell node)
{
if (node == null)
return;
// 正在加载中,不需要重复请求
if(node.Payload.LoadRequest != null)
return;
// 新建加载请求
node.Payload.LoadRequest = m_RenderTextureJob.Request(x, y, node.MipLevel);
}
TileTexture
tileTexture会设置tile的size,每个size的分辨率大小,以及padding像素
在这里我们有一个渲染队列,由于同一帧可能请求比较多,我们可以从mipmap等级高到底排序,然后控制每帧渲染数量来进行。
public void Update()
{
if (m_PendingRequests.Count <= 0)
return;
// 优先处理mipmap等级高的请求
m_PendingRequests.Sort((x, y) => { return x.MipLevel.CompareTo(y.MipLevel); });
int count = m_Limit;
while (count > 0 && m_PendingRequests.Count > 0)
{
count--;
// 将第一个请求从等待队列移到运行队列
var req = m_PendingRequests[m_PendingRequests.Count - 1];
m_PendingRequests.RemoveAt(m_PendingRequests.Count - 1);
// 开始渲染
StartRenderJob?.Invoke(req);
}
}
在处理一个具体的tile时,由于我们需要烘焙diffuse,normal,Mask(暂时没处理),我们这里使用的MRT。
然后就转化到要把page上的某个rect,画到TileTexture的某个tile上了,这里还得考虑padding这些,涉及到非常繁琐的tileoffset的计算,这里花了我不少时间。除了渲染地形,以后如果有些需要贴到地形上的贴花也在这个过程中进行。
drawtexture的shader也就是常规的blend混合,这里要注意的是,对于地形超出四层的情况,第一个四层正常渲染,第二个四层以及后面的贴花可以采用Blend One One的形式
PixelOutput frag(v2f_drawTex i) : SV_Target
{
float4 blend = tex2D(_Blend, i.uv * _BlendTile.xy + _BlendTile.zw);
#ifdef TERRAIN_SPLAT_ADDPASS
clip(blend.x + blend.y + blend.z + blend.w <= 0.005h ? -1.0h : 1.0h);
#endif
float2 transUv = i.uv * _TileOffset1.xy + _TileOffset1.zw;
float4 Diffuse1 = tex2D(_Diffuse1, transUv);
float4 Normal1 = tex2D(_Normal1, transUv);
transUv = i.uv * _TileOffset2.xy + _TileOffset2.zw;
float4 Diffuse2 = tex2D(_Diffuse2, transUv);
float4 Normal2 = tex2D(_Normal2, transUv);
transUv = i.uv * _TileOffset3.xy + _TileOffset3.zw;
float4 Diffuse3 = tex2D(_Diffuse3, transUv);
float4 Normal3 = tex2D(_Normal3, transUv);
transUv = i.uv * _TileOffset4.xy + _TileOffset4.zw;
float4 Diffuse4 = tex2D(_Diffuse4, transUv);
float4 Normal4 = tex2D(_Normal4, transUv);
PixelOutput o;
o.col0 = blend.r * Diffuse1 + blend.g * Diffuse2 + blend.b * Diffuse3 + blend.a * Diffuse4;
o.col1 = blend.r * Normal1 + blend.g * Normal2 + blend.b * Normal3 + blend.a * Normal4;
return o;
}
(这里注意采样纹理一定要自己指定mipmap等级为0,不然显卡会降mipmap等级导致变模糊,这也是我后面发现的,文章和demo都没修改)
画完后就要通知pagetable我加载完毕,并且更新cell上的加载信息。
LookUp
在pagetable每帧更新中,会将TileTexture各个Tile激活下的数据写入lookup贴图,这个lookup的尺寸跟pagetable的cell格子数一样大小,rgb分别表示,cell坐标,mipmap等级。
这里要注意几个地方,第一,Active的page只需取存在feedback上的activepage,而不需取整个TileTexture上的。第二,active的page可能会有重合的地方,这里以mipmap等级低的覆盖等级高的。由于有这两点,我起初是直接在CPU创建一张Texture2D,往里填数据,后来测试发现这样会非常慢,特别是Texture2D的Apply。后来参考UE的代码采用GPUInstance直接画上去,这里由于需要使用mipmap等级低的覆盖高的,可以使用画家算法,按mipmap排序。ue还使用了莫顿码,我这里直接使用InstanceData传入进去整个数据
var mats = new Matrix4x4[drawList.Count];
var pageInfos = new Vector4[drawList.Count];
for(int i=0;i<drawList.Count;i++){
float size = drawList[i].rect.width / TableSize;
mats[i] = Matrix4x4.TRS(
new Vector3(drawList[i].rect.x / TableSize, drawList[i].rect.y / TableSize),
Quaternion.identity,
new Vector3(size, size, size));
pageInfos[i] = new Vector4(drawList[i].drawPos.x, drawList[i].drawPos.y, drawList[i].mip / 255f,0);
}
Graphics.SetRenderTarget(m_LookupTexture);
var tempCB = new CommandBuffer();
var block = new MaterialPropertyBlock();
block.SetVectorArray("_PageInfo", pageInfos);
block.SetMatrixArray("_ImageMVP", mats);
tempCB.DrawMeshInstanced(mQuad, 0, drawLookupMat,0, mats, mats.Length, block);
Graphics.ExecuteCommandBuffer(tempCB);
shader代码
UNITY_INSTANCING_BUFFER_START(InstanceProp)
UNITY_DEFINE_INSTANCED_PROP(float4, _PageInfo)
UNITY_DEFINE_INSTANCED_PROP(float4x4, _ImageMVP)
UNITY_INSTANCING_BUFFER_END(InstanceProp)
Varyings vert(Attributes IN)
{
Varyings OUT ;
UNITY_SETUP_INSTANCE_ID(IN);
float4x4 mat = UNITY_MATRIX_M;
mat = UNITY_ACCESS_INSTANCED_PROP(InstanceProp, _ImageMVP);
float2 pos = saturate(mul(mat, IN.positionOS).xy);
pos.y = 1 - pos.y;
OUT.positionHCS = float4(2.0 * pos - 1,0.5,1);
OUT.color = UNITY_ACCESS_INSTANCED_PROP(InstanceProp, _PageInfo);
return OUT;
}
half4 frag(Varyings IN) : SV_Target
{
return IN.color;
}
这里Unity有几个坑逼的地方,首先unity调用drawMeshInstanced传入的那个矩阵他会修改里边的数据,导致我不能直接使用那个数据,因为我这里不是标准的MVP矩阵,他可能帮我转换了,我这里重新弄了一个矩阵instanceData。还有一点就是如果你在shader里不使用UNITY_MATRIX_M这个变量,unity就认为你这个不是drawInstance。所以我在shader里加了一句无意义的代码float4x4 mat = UNITY_MATRIX_M;
DrawVT
所有数据准备完毕后,现在就比较简单了。直接使用RVT贴图里的diffuse和Normal,然后参与光照计算就OK了。
half4 GetRVTColor(Varyings IN)
{
float2 uv = (IN.positionWS.xz - _VTRealRect.xy) / _VTRealRect.zw;
float2 uvInt = uv - frac(uv * _VTPageParam.x) * _VTPageParam.y;
float4 page = tex2D(_VTLookupTex, uvInt) * 255;
#ifdef _SHOWRVTMIPMAP
return float4(clamp(1 - page.b * 0.1 , 0, 1), 0, 0, 1);
#endif
float2 inPageOffset = frac(uv * exp2(_VTPageParam.z - page.b));
uv = (page.rg * (_VTTileParam.y + _VTTileParam.x * 2) + inPageOffset * _VTTileParam.y + _VTTileParam.x) / _VTTileParam.zw;
half3 albedo = tex2D(_VTDiffuse, uv);
half3 normalTS = UnpackNormalScale(tex2D(_VTNormal, uv), 1);
InputData inputData;
InitializeInputData(IN, normalTS, inputData);
half metallic = 0;
half smoothness = 0.1;
half occlusion = 1;
half alpha = 1;
half4 color = UniversalFragmentPBR(inputData, albedo, metallic, /* specular */ half3(0.0h, 0.0h, 0.0h), smoothness, occlusion, /* emission */ half3(0, 0, 0), alpha);
SplatmapFinalColor(color, inputData.fogCoord);
return half4(color.rgb, 1.0h);
}
动态更新
以上基本就能把地形通过rvt画出来了,但是这样有个基本限制,那就是我们移动的时候,如果是超大世界,那么这个pagetable对应的位置就有限。ue的解决办法是每个地形一套rvt,这样会造成,在地形边界可能出现四套rvt,这基本不能接受。天刀采用的是动态更新pagetable,也就是说pagetable对应的cell表示的范围会动态变化。
在changerect的时候,我们需要最大限度地复用TileTexture,不然需要重绘所有的TileTexture,这样会造成比较大的卡顿。这里对于changrect的rect的规范就比较有讲究了,我们需要fixed这个rect,让他尽可能地多复用pagetable。我们这是通过设置更新距离为整个可视距离的四分之一或者八分之一这种,然后通过这个四分之一去fixed可视范围center